
시작 배경
롤에서 사용자 설정 게임의 경우, RIOT API를 통해 데이터를 가져올 수 없다. 이에 따라 소속한 클랜에서 리그전을 진행할 때 매번 수기로 수치를 작성해야 하는데, 캡쳐하기만 하면 자동으로 표 형태로 만들 수는 없을까 생각해 시작했다.
사용자 인터뷰
Q. 무료로 배포된 IMG to TEXT 사이트를 사용해봤나요?
A. 해당 사이트들의 경우 숫자를 가져올 수는 있지만 이를 표 형태로 만들어주지는 않더라구요. 결국 손으로 다 써야하니까 안써요.
Q. 캡처한 이미지로 데이터를 추출한다면 어떤 형태로 나오길 바라세요?
A. 그냥 게임 끝나고 나오는 결과창에 있는 형태 그대로 나오기만 하면 되요. 왼쪽에 나온 항목이랑 오른쪽에 10명 데이터 숫자가 표로 나오면 좋겠어요.
제작 과정
OCR 라이브러리 리서치 : Tesseract
내가 주로 사용하는 언어가 Python이기 때문에 Python에서 사용할 수 있는 OCR 라이브러리를 찾아보았다. 오픈소스로 공개된 Tesseract를 사용해본 후기 글을 보고 도움을 받았다.
📥 Tesseract 설치 링크
- 나는 Windows 버전으로 다운받아서 사용함.
- 설치할 때 한글 관련 항목 모두 체크해서 다운받음.
- CMD에서 잘 구동하는지 체크하는 과정은 건너뛰었음.
이미지에서 텍스트 추출하기
작성한 코드
코드는 친절하게 소개되어있는 깃허브 내용을 참고했다.
GitHub - madmaze/pytesseract: A Python wrapper for Google Tesseract
A Python wrapper for Google Tesseract. Contribute to madmaze/pytesseract development by creating an account on GitHub.
github.com
import streamlit as st
from PIL import Image
import pytesseract
import cv2
import re
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Tesseract OCR 엔진 경로 설정
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# Load the image from file
image_path = './Test_image/테스트.png' # Replace with your image file path
image = Image.open(image_path)
# 이미지를 numpy 배열로 변환
np_image = np.array(image)
# 이미지를 회색조로 변환
gray_image = cv2.cvtColor(np_image, cv2.COLOR_RGB2GRAY)
# INTER_CUBIC을 사용하여 이미지의 크기를 변경
resized_image = cv2.resize(gray_image, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
# 이미지 노이즈 제거를 위한 가우시안 블러
blurred_image = cv2.GaussianBlur(resized_image, (3, 3), 0)
# 팽창과 침식을 위한 커널 생성
kernel = np.ones((2, 2), np.uint8)
# 이미지 침식
eroded_image = cv2.erode(blurred_image, kernel, iterations=1)
# pytesseract를 사용하여 OCR 적용
config = '--psm 4'
text = pytesseract.image_to_string(eroded_image, lang='kor+eng', config=config)
print(text.replace('\n\n','\n'))
# 텍스트 전처리
text_fix = re.sub(r"[^0-9/a-zA-Z\uAC00-\uD7A3\n\s]", "", text.replace('\n\n','\n'))
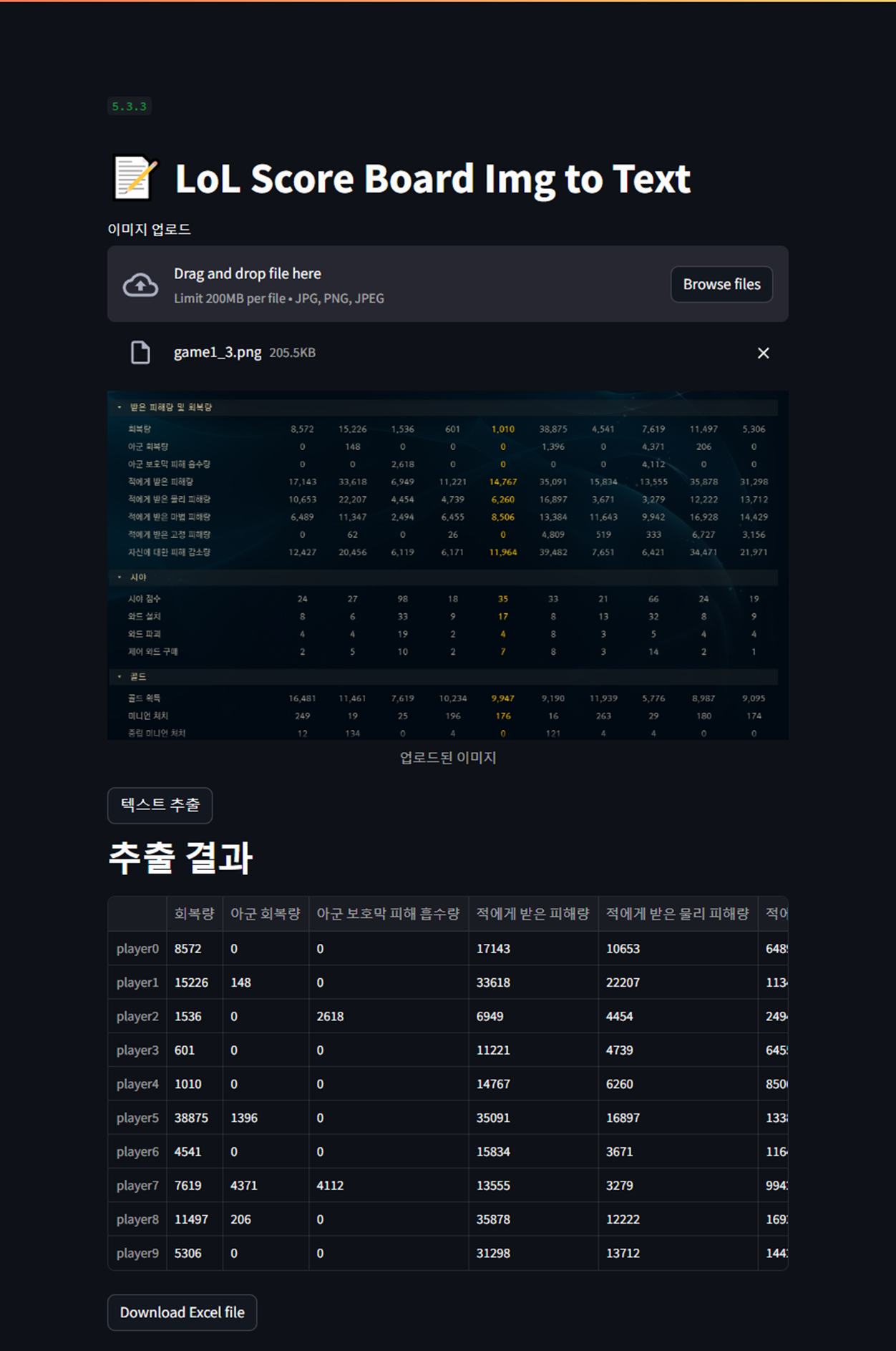
이미지 및 변환 결과
이미지를 텍스트로 변환했을 때 표로 변환할 수 있는 형태의 데이터로 변환되어 나왔다. 위 아래 불필요하게 추출된 텍스트를 제외하고, 항목이나 숫자 포맷을 통일하는 등 전처리하면 표로 나오게 해보자.


텍스트 전처리 및 DataFrame 변환
- 불필요한 특수문자 등 삭제
- DataFrame 틀 잡기 : index를 player 0~9로 설정
- 한줄에 텍스트가 20개 이하인 행은 무시
- 값들 사이에 들어간 공백을 기준으로 구분해 리스트로 만들고 양옆 공백은 삭제
# 텍스트 전처리
text_fix = re.sub(r"[^0-9/a-zA-Z\uAC00-\uD7A3\n\s]", "", text.replace('\n\n','\n'))
output = pd.DataFrame(columns = ['category']+['player' + str(x) for x in range(10)])
text_fix_line = text_fix.split('\n')
# DataFrame 변환
for text_fix_ in text_fix_line:
if len(text_fix_) < 20:
continue
text_cate_ = text_fix_[:text_fix_.find(' ')].strip()
text_data_ = text_fix_[text_fix_.find(' '):].strip()
text_data_ = text_data_.split(' ')
if len(text_data_) < 10:
continue
print(text_fix_)
value_to_remove = ''
while value_to_remove in text_data_:
text_data_.remove(value_to_remove)
text_input_ = [text_cate_] + [x.strip() for x in text_data_]
output.loc[len(output)] = text_input_
output = output.transpose()
output.columns = output.loc['category'].tolist()
output = output.drop('category')
print(output)

웹 배포 결과
언제든 쓸 수 있어야 해서 웹으로 배포하려고 Streamlit을 사용했는데, 아쉽게도 스트림릿에서는 내가 사용한 Tesseract의 버전을 지원하지 않는 문제가 있었다. AWS를 사용해 배포하는 방법을 찾았지만 클랜에서 사용하지 않기로 한 뒤로는 관리하기 어려울 것 같아서 streamlit으로 배포했다. 버전 문제로 변환이 안되지만…🤣
- Streamlit Cloud에서 배포할 때는 'packages.txt'를 사용했다. (참고글)
- Streamlit: super-son-lol-scoreboard-img-to-text.streamlit.app/
회고
OCR 사용 과정이 즐거웠다.
만드는 과정 자체가 즐거웠고 실제로 변환해서 엑셀 파일로 다운로드 되는 것까지 완성했을 때는 다했다는 만족감을 느꼈다. OCR은 처음 사용해보는데 매력있는 분야라는 생각이 들었다.
좋은 이미지가 좋은 결과를 가져온다.
제작을 위해 클랜에서 약 20장의 이미지를 제공받았는데, 어떻게 찍었는지 화질은 어떤지에 따라 결과가 다르게 나왔다. 이번 테스트에서는 롤 게임결과를 사용해서 화질과 찍은 부분 외에 품질을 크게 변화시킬 수 있는 방법은 잘 떠오르지 않았다.
그러나 사용하려는 이미지가 비슷하다는 점에서 롤 게임결과 이미지를 모아 학습시킨 OCR 모델을 만들면 포맷을 고정하거나 하지 않아도 더 좋은 결과를 추출할 수 있지 않을까?
사용자는 차갑다…
사이트 배포 후 클랜에 공유해 실사용에 도입했으나 1주일만에 수기로 작성하는 것으로 결정됐다. 2가지 정도 이슈가 있었다.
- 단축키를 사용해도 이미지를 포맷대로 캡처하는 것이 생각보다 불편하다.
- 10번 중 1번 정도 값이 정확하게 안나올 때가 있는데, 붙여넣고 결국 검수해야 하는 거라면 수기로 쓰겠다.
나름 인터뷰해서 필요한 기능들을 구현하고 손이 덜 가게 했다고 생각했는데 실제 배포했을 때의 반응은 냉정했다. 서비스를 만든다는 게 어렵다는 걸 체험했다.
만났던 문제들
불필요한 텍스트로 인한 변환 실패 : 이미지 포맷 통일
롤 클라이언트를 [ Alt+PrtSc ] 로 화면을 캡처하면 게임결과와 무관한 글자들이 같이 들어가면서 변환한 결과가 이상해지거나, 포맷이 동일하게 나오지 않는 문제가 있었다. 이에 따라 위 테스트한 이미지처럼 포맷을 통일해 해결했다. [ Win+Shift+S ] 단축키로 캡처해서 사용하는 방법을 추가로 안내했다. 완벽한 해결은 아니지만… 😥

배포 환경 문제 : Streamlit ⇒ AWS
Streamlit Cloud에서 Tesseract 5.x 버전을 사용하는 법을 못찾아서 로컬에서의 결과와 다르게 결과가 나타났다. AWS 프리티어 서버를 사용해 원하는 버전의 Tesseract를 깔아서 배포하면 해결할 수 있다. (아래 코드 참고)
sudo apt update
sudo apt install -y software-properties-common
sudo add-apt-repository ppa:alex-p/tesseract-ocr-devel
sudo apt update
sudo apt install -y tesseract-ocr
tesseract --version